Unmute.sh by kyutai
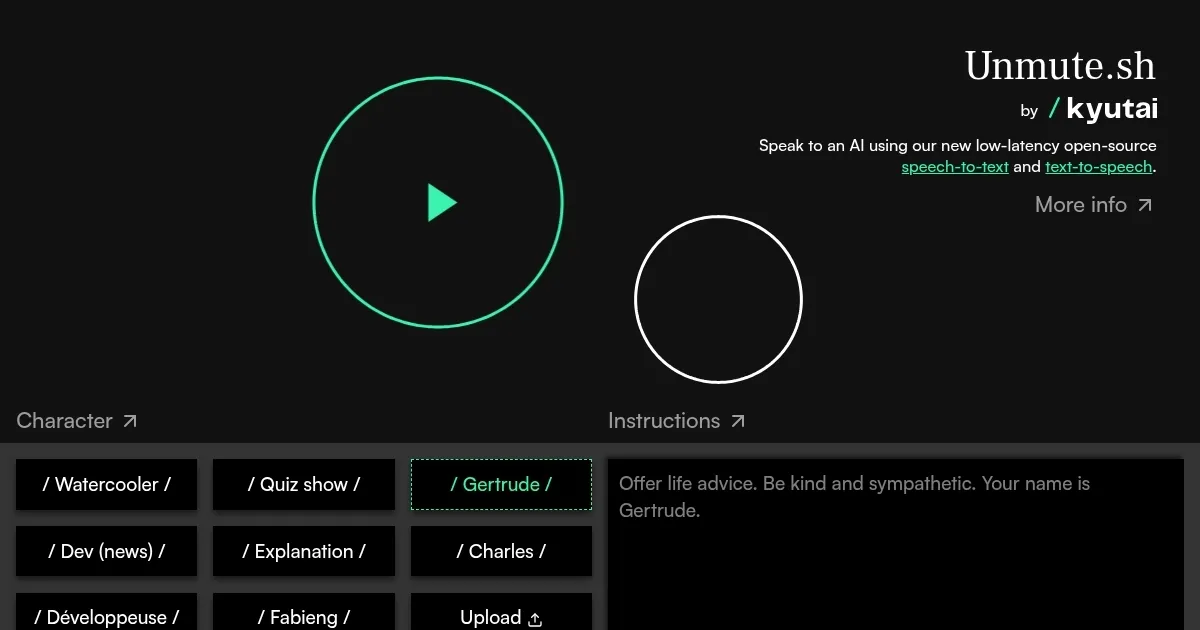

Unmute is an open-source system by Kyutai that enables text-based large language models (LLMs) to handle real-time voice interactions through speech-to-text (STT) and text-to-speech (TTS) integration. It supports any LLM, offering developers flexibility to add voice capabilities without retraining models. The STT uses semantic Voice Activity Detection (VAD) to detect when a user finishes speaking, achieving response latencies of 200-350 milliseconds. The TTS streams audio before the full text response is generated, ensuring smooth conversations. Unmute’s demo at unmute.sh showcases features like function calling, where specific commands (e.g., “bye” to end a call) trigger actions, and a “Dev (news)” mode that fetches live data via APIs.
The system’s modularity allows integration with LLMs like Mistral or Llama, making it versatile for developers. Its open-source nature, available on GitHub, means no cost for access, unlike Grok, which is tied to xAI’s ecosystem, or ElevenLabs, which focuses on premium TTS. Unmute’s STT accuracy is high, even with varied speech patterns, and its voice customization feature lets users create unique voices from 10-second audio samples. The system relies on WebSocket connections for real-time communication, which ensures low latency but requires stable internet.
Drawbacks include limited voice variety compared to ElevenLabs, which offers more emotive options. Non-developers may find the setup complex, as it’s geared toward those with technical skills. Some users report occasional connection drops during peak usage. The demo is accessible but lacks a polished interface for casual users. Developers can leverage Unmute’s code to build custom applications, while end-users can test it online.
For best results, ensure a strong internet connection to avoid WebSocket issues. Developers should explore the GitHub documentation for integration tips. Casual users can try the demo to gauge its fit for personal projects.
What are the key features? ⭐
- Semantic VAD: Detects when a user finishes speaking for smooth turn-taking.
- Real-Time STT: Transcribes speech instantly with high accuracy.
- Streaming TTS: Generates audio before full text response, reducing latency.
- Modular Design: Integrates with any text LLM without retraining.
- Voice Customization: Creates unique AI voices from 10-second audio samples.
Who is it for? 🤔
Examples of what you can use it for 💭
- Developer: Integrates Unmute with an LLM to build a voice-activated app.
- Customer Support Manager: Uses Unmute for real-time AI hotline responses.
- Accessibility Advocate: Deploys Unmute to aid speech-based tech access.
- Game Designer: Creates a voice-driven NPC for tabletop RPGs.
- Content Creator: Builds a podcast bot with a custom voice via Unmute.
Pros & Cons ⚖️
- Works with any LLM
- Accurate speech detection
- Custom voice in 10 seconds
- Limited voice variety