Lexy
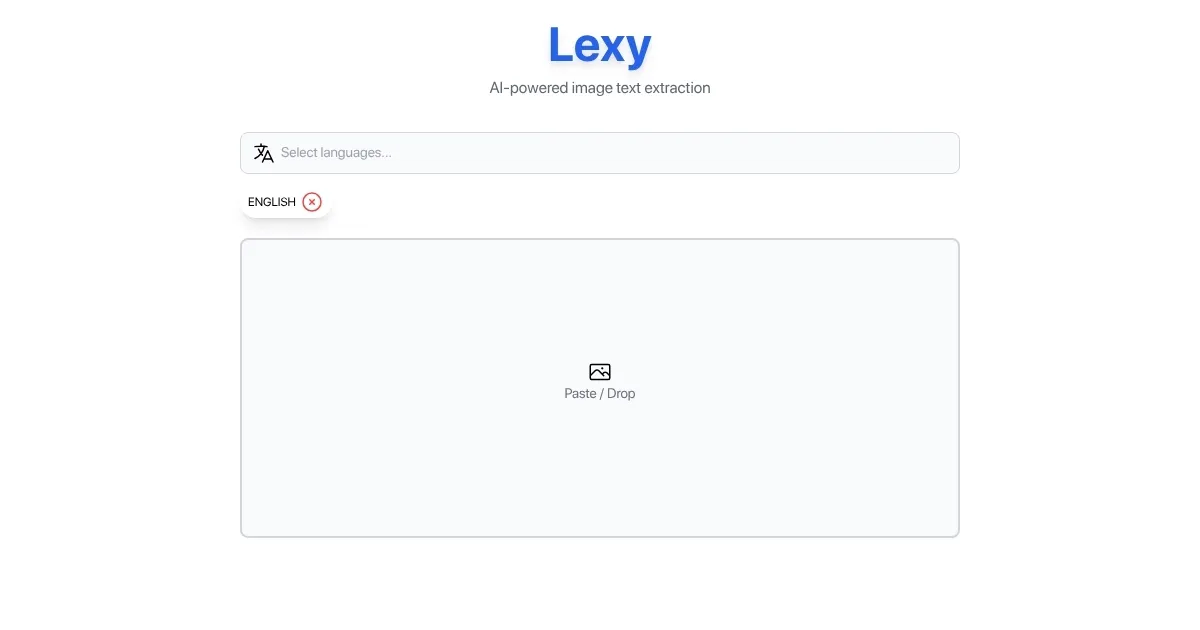

Lexy is an open-source, browser-based OCR tool that extracts text from images offline using Tesseract.js and WebAssembly. It supports over 50 languages, including English, Chinese, and Arabic, and operates without cloud connectivity for enhanced privacy. Users upload an image, select a language, and receive extracted text in seconds. The tool is free, lightweight, and hosted on GitHub by thewh1teagle.
The core functionality relies on Tesseract.js, a JavaScript port of the Tesseract OCR engine, paired with WebAssembly for efficient in-browser processing. Lexy handles printed text well, achieving high accuracy on clear images like book pages or typed documents. It supports a wide range of image formats, including PNG and JPEG, and processes files locally, ensuring no data leaves the user’s device. The interface is minimal, with a drag-and-drop uploader and a language selector, making it accessible for beginners.
Compared to competitors, Lexy stands out for its offline capability. Google Lens offers similar OCR but requires an internet connection and collects user data. ABBYY FineReader provides superior accuracy for complex documents and handwriting but is a paid desktop solution. Adobe Scan integrates OCR with PDF tools but requires a subscription for full features. Lexy’s free, open-source model appeals to users prioritizing cost and privacy.
Accuracy varies by image quality. Clear, printed text yields near-perfect results, but handwritten or low-resolution images can reduce accuracy to 70-80%. The tool lacks advanced features like image preprocessing or batch processing, which limits its use for large-scale tasks. No official releases or extensive documentation exist, though GitHub discussions provide some community support.
Lexy suits users needing quick, private text extraction from images. For best results, use high-quality images and test with a simple document first. If advanced features are needed, consider ABBYY or Adobe Scan, but for straightforward, cost-free OCR, Lexy delivers.
What are the key features? ⭐
- Offline Processing: Extracts text from images entirely in the browser, ensuring privacy.
- Multilanguage Support: Supports over 50 languages, including Arabic, Chinese, and Welsh.
- WebAssembly Speed: Uses WebAssembly for fast, efficient OCR without taxing system resources.
- Simple Interface: Features a drag-and-drop uploader and language selector for ease of use.
- Open-Source: Freely available on GitHub, with community-driven updates and transparency.
Who is it for? 🤔
Examples of what you can use it for 💭
- Student: Digitizes handwritten class notes for easy editing or sharing.
- Researcher: Extracts text from scanned historical documents for analysis.
- Traveler: Converts foreign-language signs into readable text offline.
- Developer: Integrates Lexy’s open-source code into custom applications.
- Librarian: Pulls text from old book pages for digital archiving.
Pros & Cons ⚖️
- Free and open-source
- Offline for privacy
- Supports many languages
- Limited handwriting accuracy