ImageBind by Meta
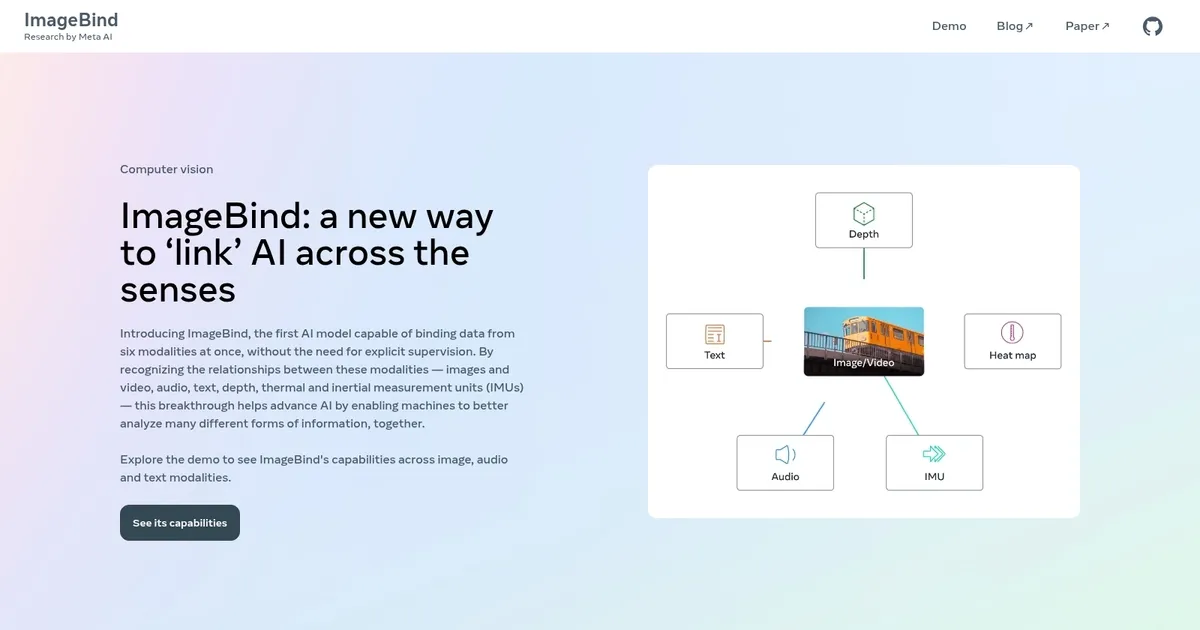
ImageBind is a powerful AI model that can simultaneously bind data from six different modalities: images and video, audio, text, depth, thermal, and inertial measurement units (IMUs). As such, it adeptly recognizes the relationships between these diverse forms of data without explicit supervision — essentially allowing machines to analyze and understand a wide array of information in unison.
ImageBind’s ability to process and link these multimodal inputs can significantly advance AI applications, enabling more comprehensive and intuitive machine analysis of complex sensory data.
Beyond processing information from multiple senses, ImageBind excels in creating a unified embedding space that can link these varied sensory inputs, mirroring the human ability to bind a whole sensory experience from a single image. This capability extends the model’s utility across various applications, enabling upgrades for existing AI models to support inputs from any of its six recognized modalities.
This advancement opens up new possibilities in fields like audio-based search, cross-modal search, multimodal arithmetic, and cross-modal generation. Notably, ImageBind has set a new standard in state-of-the-art (SOTA) performance for emergent zero-shot and few-shot recognition tasks across modalities — boasting superior results even when compared to specialized models trained for those specific modalities.