Firecrawl
A powerful tool designed to simplify web scraping and crawling
Firecrawl is a powerful tool designed to simplify web scraping and crawling. By converting websites into Large Language Model (LLM)-ready data, it enables users to harness clean, structured information from any online source. This open-source platform is designed for developers as well as businesses seeking efficient methods to gather and process web data.
Beyond text-heavy websites, Firecrawl can also “handle” dynamic, JavaScript-heavy websites. Whereas traditional scrapers often struggle with such sites, that is not a problem for Firecrawl — which can even deal with single-page applications with infinite scrolling.
Firecrawl also offers seamless integration with popular tools and frameworks, such as LangChain, LlamaIndex, and so on. This integration capability allows for the efficient building of AI apps that rely on clean, structured data.
Moreover, Firecrawl’s open-source “nature” ensures a collaborative environment for continuous improvement. Developers can contribute to its GitHub repository to enhance features and address issues collectively. Such a community-driven approach makes sure that Firecrawl evolves to meet the changing demands of web scraping and data extraction.
In summary, Firecrawl is a versatile and robust solution for web data extraction, catering to an array of professional needs. Its ability to handle dynamic content, coupled with seamless integrations and an open-source foundation, makes it a useful asset in the toolkit of developers, data scientists, and businesses alike. Check it out.
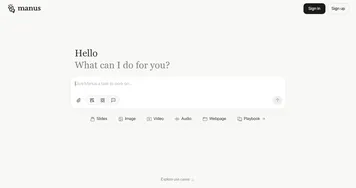
Homepage Screenshot 📸

Video Overview 🎬
What are the key features? ✨
- Dynamic content handling: Efficiently extracts data from JavaScript-heavy websites, including single-page applications and infinite scroll pages.
- Seamless integrations: Compatible with popular AI development tools like LangChain and LlamaIndex, facilitating streamlined workflows.
- It's open-source: Encourages community contributions for continuous enhancement and adaptability to evolving web technologies.
- Comprehensive data extraction: Converts entire websites into LLM-ready markdown or structured data, ensuring no valuable information is missed.
- User-friendly API: Provides a straightforward API that allows users to perform complex scraping tasks with minimal configuration.
Who is it for? 🤔
Examples of what you can use it for 💡
- Automate the extraction of data from different websites to integrate into applications or databases
- Data scientists can use it to gather large datasets from the web for analysis, research, or training machine learning models
- Digital marketers can monitor competitor websites and gather market intelligence to inform strategies
- Researchers can use it to collect information from multiple online sources to support academic or industry research projects
- Content aggregators can compile data from various websites to create content hubs or directories
Pros & Cons ⚖️
- Effectively extracts data from web apps that rely on JavaScript
- Works seamlessly with a variety of AI tools and frameworks
- It's open-source, which means community-driven development
- Users new to web scraping may require time to fully understand and utilize Firecrawl's capabilities
FAQs 💬
Ready to try Firecrawl?
A powerful tool designed to simplify web scraping and crawling
Visit Firecrawl